The LLM Function Design Pattern
Introduction
As large language models (LLMs) become integrated into production systems, developers increasingly face structural challenges. The logic for prompting, input preparation, output parsing, and tool orchestration is often fragmented across templates, helper classes, and loosely defined conventions.
This fragmentation creates friction:
- Prompt templates exist separately from the code that uses them
- Inputs are manually interpolated into strings
- Output parsing relies on assumptions or fragile regex
- Tool dependencies are not explicitly declared
- System behavior becomes difficult to understand or modify
The result is that even relatively simple LLM-backed features can become hard to maintain. Refactoring is risky. Testing is incomplete. Modifying behavior means reading through multiple files and formats to find where things are defined.
The LLM Function Design Pattern addresses these issues by consolidating all LLM-related behavior into a single class. It treats each function as a discrete unit with well-defined inputs, outputs, prompt instructions, and tool dependencies. This approach brings consistency, testability, and modularity to the development of AI-powered functionality.
The Problem: Scattered Structure and Unclear Interfaces
The conventional approach to integrating LLMs often relies on implicit coordination across loosely coupled parts:
- Prompts are maintained in external files or inline strings with ad hoc formatting
- Inputs are injected via string interpolation
- Output parsing is performed with regex or loosely enforced schemas
- Tool usage is undocumented or embedded within free-text instructions
This structure tends to produce the following issues:
- Drift between template and code — changes in field names silently break functionality
- No type validation — field mismatches or missing inputs are not caught at compile time
- Hard-to-audit logic — inputs, prompts, and tools may be defined in separate places
- Difficult to test — behavior can’t be reliably mocked or asserted
- Poor reusability — each new behavior requires manual assembly of the same core mechanics
The lack of a unified abstraction makes these systems hard to evolve or scale.
The LLM Function Design Pattern
The LLM Function Pattern provides a single, consistent structure for modeling LLM-backed functionality. Each function consists of:
- A typed Request record (structured inputs)
- A typed Response record (structured outputs)
- A static list of available tools, if needed
- A YAML-based template containing system and user instructions
This structure consolidates prompt-related logic into a single unit that behaves like any other software function: it accepts inputs, produces outputs, and has a clear execution contract.
The pattern draws on established software design principles:
- Command pattern — encapsulates behavior as a single object with inputs and outputs
- Template method pattern — defines reusable structure in a base class, with specifics provided by each function
The goal is not to introduce new frameworks, but to reduce incidental complexity and promote a maintainable, traceable development model.
A Complete Example
A Complete Example
package com.example.llm.functions;
import com.example.llm.core.LlmFunction;
import com.example.llm.core.Tool;
import com.example.llm.core.ContentTools;
import java.util.List;
public class transform_content extends LlmFunction<
transform_content.Request, transform_content.Response> {
public record Request(
String user_instructions,
String original_content,
String content_type,
String authoring_guidelines,
String content_metadata,
List<String> reference_materials) {}
public record Response(
String transformation_summary,
String transformed_content) {}
public static final List<ToolDefn> TOOLS = List.of(
ContentTools.textValidatorTool,
ContentTools.readabilityScorerTool,
ContentTools.languageSimplifierTool,
ContentTools.formattingNormalizerTool
);
public static final String TEMPLATE = """
systemMessage: |
You are a professional content transformer. You are given the original content,
its type, formatting metadata, authoring guidelines, and reference materials.
Use the available tools to:
- Improve clarity and structure
- Match the tone and format in the guidelines
- Enforce domain terminology
- Ensure consistency and correctness
userMessage: |
Follow the user instructions to transform the content.
── Supplied Context ────────────────────────────────────
- Content type: identifies the content form (e.g., FAQ, report)
- Authoring guidelines: formatting and stylistic requirements
- Metadata: tags, language, audience level
- Reference materials: domain-specific knowledge or prior documents
Requirements:
1. Preserve original intent
2. Follow instructions precisely
3. Apply formatting standards
4. Only change what's necessary
5. Explain what was changed and why
Return:
- transformation_summary
- transformed_content
""";
Anatomy of an LLM Function
Each function consists of four components: inputs, outputs, tools, and a template.
While the examples in this article use Java syntax and idioms (e.g., record types, static declarations), the principles behind the LLM Function Design Pattern are language-agnostic. The same structure — typed inputs, typed outputs, declarative tooling, and conceptual prompts — can be applied in any modern programming language that supports basic type definitions and serialization.
Inputs
The Request type defines the function’s input space. It is a plain, typed record with no behavior — used solely for transporting input values to the language model.
Input Formatting Considerations
During early development, we explored different ways of representing input values in the prompt. One approach used section headers (e.g., ### USER INSTRUCTIONS) to organize different types of data. However, this format introduced ambiguity — the model often misinterpreted section breaks, or failed to distinguish between values and instructions.
We ultimately adopted JSON serialization of the Request object as the default mechanism. All major LLMs handle structured JSON reliably, and it eliminates ambiguity. The full Request is serialized and appended to the prompt in raw form. This clearly separates input data from template instructions and makes it easy to reason about prompt assembly.
This change also simplified the code: instead of interpolating fields into a custom prompt, the executor just serializes the input and appends it.
Field Naming
Field names are important. They appear in the prompt and affect how the model interprets each value. Descriptive names like user_instructions or content_metadata improve model performance. Vague or generic names lead to degraded accuracy and unpredictable outputs.
Note: snake_case is used for field names to emphasize their role in serialized output. This breaks from Java’s typical camelCase style but serves as a visual indicator that the data is intended for the model.
Outputs
The Response type defines the structure of the expected output from the model. It is also a Java record, and should match the return schema described in the prompt.
Advantages include:
- Predictable deserialization
- Compile-time field validation
- Easy integration into downstream logic
In environments where the LLM supports function calling or structured outputs, this pattern aligns naturally. Most such systems require a valid JSON schema that describes the expected output format. Java record types — being immutable, flat, and well-typed — can be automatically converted into JSON schemas using standard libraries. These schemas can then be attached to the LLM request to constrain the model’s output generation.
This provides a second layer of validation: the model is not only prompted to return structured output but is also given an explicit target schema to match. This approach is particularly effective when working with OpenAI function calling, Claude tool use, or similar features from other LLM providers.
Like input fields, output field names should be chosen carefully to align with what the prompt instructs the model to return.
Tools
Some LLM functions require access to external tools — such as validators, normalizers, or knowledge accessors — which the model can call through an execution layer.
In this design, tools are declared via a public static field in the function:
public static final List<ToolDefn> TOOLS = List.of(...);This approach is minimal and straightforward. The executor is expected to look for this field by convention.
No Getter?
A getTools() method was intentionally not added to the interface. While that would offer more structured access, it introduces boilerplate that detracts from clarity. In this version of the pattern, we prioritize readability and simplicity over strict enforcement. This does introduce a potential runtime risk if the field is missing or malformed, but the tradeoff was considered acceptable.
In environments where stronger type guarantees are needed, developers can extend the base class or adopt an interface pattern to enforce tool exposure.
Template
The prompt is defined as a YAML string with two sections:
- systemMessage: High-level behavior and model role
- userMessage: Task-specific instructions and requirements
Unlike many prompt systems, there are no placeholders like {{field}} in the template. The model references input fields conceptually — the actual values are delivered via the serialized JSON appended to the end of the prompt.
This eliminates mismatch between code and prompt, and prevents runtime failures due to missing placeholders. It also makes the prompt more natural to write and easier to review.
Execution
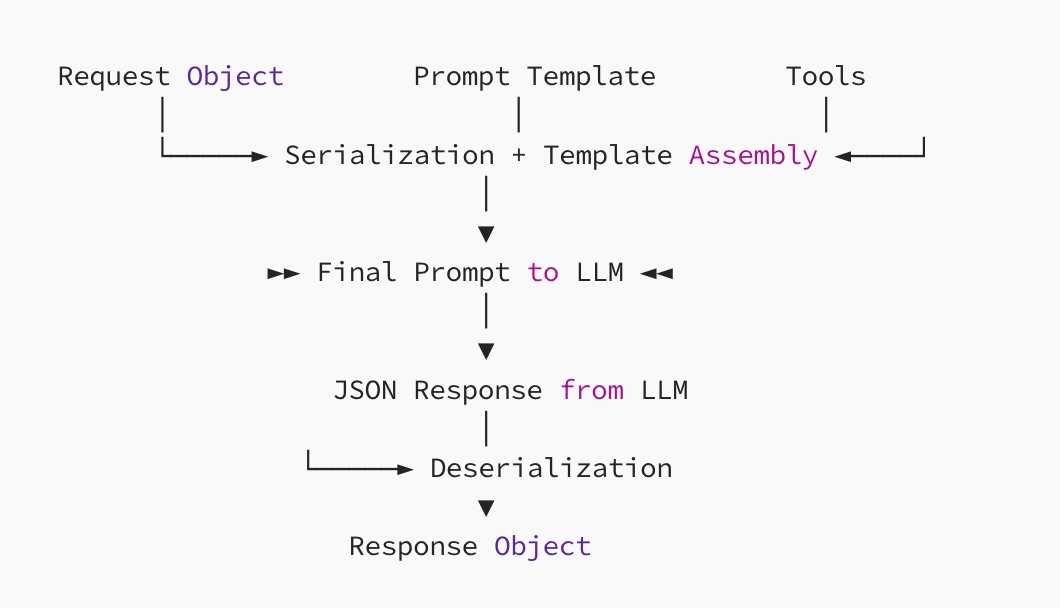
Executing an LLM function involves four basic steps:
- Serialize the Request object into JSON
- Append it to the YAML prompt template
- Submit the full prompt and declared tools to the model runtime
- Parse the response into the Response type
Diagram: Prompt Assembly Flow
The actual executor implementation will vary based on the host environment (e.g., Java app, Python pipeline, agent orchestrator). This article does not prescribe a specific interface. In many cases, a coding agent can generate the executor code required for a given platform.
Optimized for Coding Agents
This pattern is structured to support code generation and automation by LLM-based coding agents. Because each function includes:
- A consistent layout (inputs, outputs, tools, template)
- Descriptive type names and field structures
- A readable, self-contained prompt definition
It becomes straightforward for agents to generate or modify functions programmatically.
For example, you can provide this article to a coding agent and request:
“Create an LLM function that classifies support tickets by urgency and assigns priority levels.”
The agent should be able to produce:
- A new Request record with the necessary fields
- A matching Response type
- A tool list (if needed)
- A YAML template with appropriate task instructions
Later, if changes are needed, the agent can update the function safely:
“Add a severity_score output to the response and update the instructions.”
“Include a tone normalizer tool.”
“Refactor the prompt to preserve informal language.”
Because everything is defined in one file with predictable structure, agent-driven edits can be applied reliably.
Manual Prompt Editing Should Be Avoided
In production environments, we discourage direct editing of the prompt template.
- Manual edits introduce drift between input fields and instructions
- Accidental changes to formatting or language can degrade model performance
- Edits are difficult to validate and trace
Instead, prompt changes should be treated as part of the function’s source. If issues arise, they can be described clearly:
“This function failed to apply the formatting rules consistently. Update the prompt to emphasize formatting accuracy.”
A coding agent or structured editor can then regenerate the YAML with the necessary modifications — preserving structure and alignment with the rest of the function.
Conclusion
The LLM Function Design Pattern provides a consistent, maintainable structure for LLM-based behavior:
- Structured, typed inputs and outputs
- Explicit tool declarations
- Conceptual, placeholder-free templates
- Clear execution flow
This pattern improves testability, reliability, and long-term maintainability. It also enables tool-assisted and agent-driven development, reducing manual effort and configuration errors.
As LLMs become part of the core application logic in modern systems, this level of structure is necessary — not just for correctness, but for scaling development practices across teams and services.
Writer’s Note
This article was authored by me based on practical experience designing and implementing LLM-backed systems. I used GPT to assist with editing and refining the language for clarity, structure, and tone — but all architectural decisions, patterns, and examples reflect my own work and reasoning.
Note: Cross-posted from Medium

Further Reading

Customized Plans for Real Enterprise Needs
Gentoro makes it easier to operationalize AI across your enterprise. Get in touch to explore deployment options, scale requirements, and the right pricing model for your team.